Introduction to Linux Device Tree
Most modern laptop or desktop computers have their peripheral devices (storage, media, or cameras) connected to the main processor through a peripheral bus such as PCIe or USB. Windows or Linux operating systems running on the computer can discover the connected peripherals through a process called enumeration or ‘plug and play’. This provides information about device type, manufacturer and device configuration thus enabling the OS to load the appropriate drivers for the device and making device operational.
However, in embedded systems, this is not the case as many peripherals are connected to the main processor using busses such as I2C, SPI, and UART which do not support enumeration.
To enable the system to recognize the peripheral devices in an embedded system, developers use a Linux Device Tree which is used to provide the hardware description for the operating system. Prior to using device tree, developers would compile the hardware description into the linux kernel and modify the kernel for each change in platform or peripheral device.
What is a Device Tree?
A Device Tree is a tree data structure with nodes that describe the devices in a system. Each node has property/value pairs that describe the characteristics of the device being represented. Each node has exactly one parent except for the root node, which has no parent.
Each node in the Device Tree is named according to the following convention: <name>[@<unit-address>].
<name>is a simple ASCII string and can be up to 31 characters in length. In general, nodes are named according to device type it represents. A node for a 3com Ethernet adapter would use the nameethernet, not3com509.<unit-address>component of the name is specific to the bus type on which the node resides. The<unit-address>must match the first address specified in the reg property of the node. If the node has no reg property, the@<unit-address>must be omitted and the<name>alone differentiates the node from other nodes under the same level in the tree hierarchy. In case<name>is used without@<unit-address>, the<name>shall be unique within the same level in the tree hierarchy.
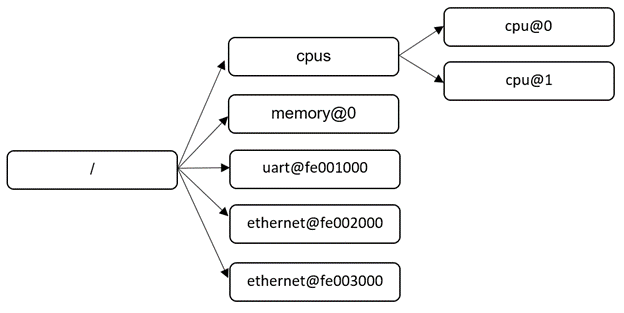
Figure 1 represents simple tree:
- The nodes with the name
cpuare distinguished by theirunit-addressvalues of0and1. - The nodes with the name
ethernetare distinguished by their unit-address values offe002000andfe003000.
A node in the Device Tree can be uniquely identified by specifying the full path from the root node, through all descendant nodes, to the desired node.
The convention for specifying a device path is: /node-name-1/node-name-2/node-name-N.
Each node in the device tree has properties that describe the characteristics of the node. Properties consist of a name and a value. A property value is an array of zero or more bytes that containz information associated with the property.
With the Linux Device Tree, the developers can create a single linux kernel image specific to a processor architecture and create multiple device tree images specific to a platform or a product. This makes it much easier to support and update the peripheral changes in various products and platforms that one desires to support.
In x86 based platforms, ACPI is commonly used to describe the hardware peripherals and it can be used with or without the Linux Device Tree. However, in non-x86 platforms such as ARM based systems, Linux Device Tree is becoming the common method of enumerating hardware peripherals.
How is Device Tree data managed?
Data from the Linux Device Tree can be shown in multiple different ways. Usually, the device tree data is in a format that is readable to humans in .dts or .dtsi source files. The Linux kernel pre-processes the dts files before passing them to the device tree compiler. The source code of the device tree is compiled into a .dtb blob file in a binary format, this format is generally called a Flattened Device Tree (FDT). With this data, the Linux OS is able to find and identify devices in the system. The raw form of the FDT is accessed by the OS during very early stages of the system booting up, but is then further expanded into a kernel data form called the Expanded Device Tree (EDT) so that it can be accessed later during and after the booting up of the system more efficiently.
As of today, device tree support is enabled in linux kernel for Microblaze, Sparc, ARM, PowerPC and x86 architectures. To unify the handling of description of platforms in various kernel architectures, there is interest to extend device tree support to other platforms.
Device Tree Advantages and Disadvantages:
In summary, here are the advantages and disadvantages of Linux Device Tree.
Advantages of the Linux Device Tree include:
- It makes changing the configuration of parts of the system very simple without having to recompile any of the linux kernel source code.
- Easier support for new/additional hardware.
- Can reuse
.dtsfiles that are already existing within the system and can override old functionality. - It makes it easier to understand the descriptions of hardware peripherals.
However, disadvantages include:
- Creation of
.dtsfiles require extensive knowledge of hardware and thus may not be easy to create. - Figuring out all the necessary syntax to match the intended system function may be difficult even if the user knows all the bus and device details.
We trust this generic insight into Linux Device Trees is helpful for your system development. Tauro Technologies implements and customizes device trees as part of Board Support Package (BSP) development and board bring-up.
Interested to know more? Get in touch with us for details




